Data Filter
A key feature of Presence is the ability to filter data based on exception rules. These exception rules allow you to trigger different actions within a Presence Task depending on what has happened with your business data. For example, to perform different functions when new, changed or deleted data is detected.
Exception reporting is vastly superior to historical reporting methodologies where large daily and weekly reports are produced and the recipient must sift the data manually looking for exceptions.
Contents
Presence Deviation Engine
The technology that enables this facility is called the Presence Deviation Engine (PDE). The Date Filter task element allows the configuration of the PDE data change or exception rules.
Certain Presence Task elements, such as the Object Monitor and POP Scanner have PDE technology built into them allowing you to automatically filter out files / e-mails which have been processed before.
For all other types of data - for example data returned by an SQL Query, XML Query or Web Service Call you create PDE exception rules by adding a Data Filter node.
Creating a Data Filter
To create a Data Filter in your Task just drag the Data Filter Task Element into your Task from the Data Access List:
http://www.international-presence.com/wikidocs/images/data_filter_element.png
{kind=link}
You will then be presented with the following input dialog:
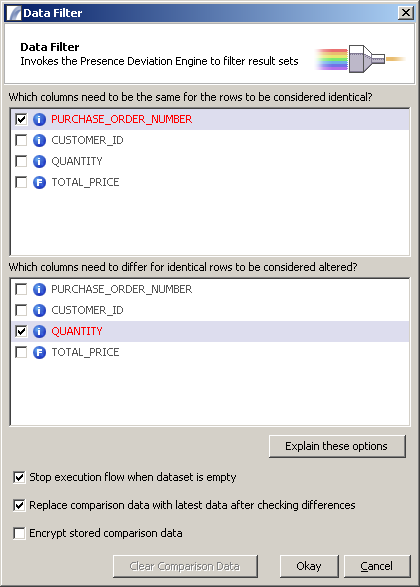
http://www.international-presence.com/wikidocs/images/data_filter_dialog.png
{kind=link}
This allows you to identify:
- Which columns identify unique rows
- Which columns identify columns that may change their values.
For example, the columns listed above describe a purchase order. The PURCHASE_ORDER_NUMBER is always unique - there can only be one row per purchase order. Therefore we know that whenever we see a new PURCHASE_ORDER_NUMBER the record can be considered to be new.
However, it's possible that records may be altered by our sales system if the customer needs to modify the quantity after the purchase. Therefore if we want to identify changed records we need to keep an eye on the QUANTITY field. The CUSTOMER_ID will never change, and we are not interested in changes to the TOTAL_PRICE.
Other options available are:
- Stop execution flow when dataset is empty - if no data is available when the Data Filter is executed the Task will stop executing that Execution Path. If there is data but it does not match the filter criteria - for example there is no new data to process - that path will not be executed. Otherwise all paths will execute with empty data.
- Replace comparison data with latest data after checking differences - This is the default option and allows "rolling" comparison data. The alternative is fixed comparison data so comparisons are made against a static base dataset.
- Encrypt stored comparison data - if selected data will be encrypted before being written to the Presence database.
- Clear Comparison Data - clears any existing comparison data for this node. The next time it runs any data seen will be considered new.
Here is what the Data Filter looks like within a Task:
http://www.international-presence.com/wikidocs/images/data_filter_in_task.png
{kind=link}
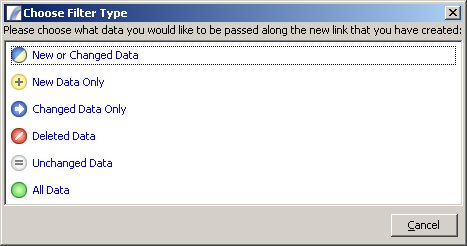
When joining the Data Filter to a subsequent node you will be prompted to specify which Data Set you would like to be passed to that Node in the Presence Context:
http://www.international-presence.com/wikidocs/images/data_filter_datatype_prompt.png
{kind=link}
And the selection will be illustrated with an icon on the link, as in the following example:
http://www.international-presence.com/wikidocs/images/data_filter_in_task_2.png
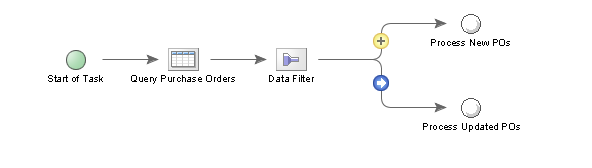{kind=link}
In this case any data considered "new" - i.e. with a PURCHASE_ORDER_NUMBER that has not been seen before - will be passed to the Node labelled "Process New POs". Any data considered "changed" - meaning it contains a previously recognised PURCHASE_ORDER_NUMBER but the QUANTITY field has changed since the last query - will be passed to the "Process Updated POs" Node.
Comparison Data Information
The comparison data is stored internally in a table called APP.FILTERCOMPARISONDATASTORE. Each data filter node has its own record which contains all previously seen data in the form of a BLOB field.
When importing and exporting Tasks you will be given the option to also export (or import) the comparison data associated with the Task.
Snapshot or Base Data
The Data Filter takes a snapshot of the data returned by your SQL or XML queries. This snapshot we refer to as the PDE "Base Data". When a Task runs again, it checks the Base Data against the new data from the query. Depending on the rules you have setup in the Data Filter it can then take one or more different actions. For example we can take one set of actions if there are New rows of data, another set of actions if data has Changed, another if we find that some data has been removed from the list and so on.
Without a Data Filter node, Presence will continually report on all items returned by the query.
The Base Data is NOT saved until the task has completed. If a task fails due to an exception error (either in Debug Mode or live) the Base Data is not updated.
Data Filter | Require Columns | Append Data Column | Multiple Column Appender
Drop Column | Drop Row(s) | Calculate Column Aggregate | Dataset Splitter | Merge Data
Create Data Table | Clear Data Table | Sort Data Table | Drop Duplicate Rows | Store Data Table | Retrieve Data Table
Task Elements > Data Table Nodes > Data Filter