Data Table
Contents
Data Table
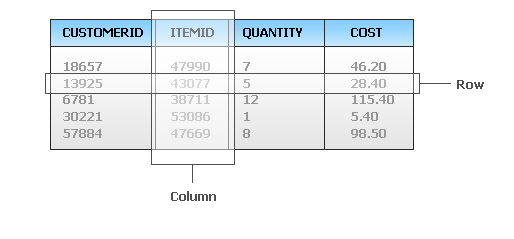
The Data Table is an object stored in memory as part of the Presence Context. It consists of a series of rows divided into named columns:
http://www.international-presence.com/wikidocs/images/data_table_view.png
{kind=link}
Populating the Data Table
The Data Table is automatically populated and appended by Query Task Elements. For example the SQL Query Node will populate the Data Table with the results of the database query, using the Column names and values that are returned in the record set.
Merging Data Tables
The Merge Results Node will merge one ore more Data Tables with either horizontal, vertical or cross-reference strategy.
Joining New Results
If a Data Table is already present in the Presence Context and a new query is performed, the results will be appended to the existing Data Table. If the results of the current (incoming) Data Table are referenced in the new query, the new results will be joined in a logical fashion. For example:
Query A creates a Data Table with the columns 'A', 'B' and 'C'.
This joins to Query B, which returns a Data Table with the columns 'D' and 'E'.
If Query B contains a reference to Column 'A' (for example in the WHERE clause), the query will be repeated for each possible value of 'A' and the subset will be joined to the correct records.
Iteration Strategies
Presence uses implicit iteration. This means that if a Task Element's settings contain a reference to one or more column names, the Task Element's functionality will be repeated for each unique value for the column(s) referenced.
For example, the Send Email node allows you to use a Column reference to form the subject (as well as the message body, attachments and recipients). Imagine we have a Data Table which contains a Column named 'EMAIL_SUBJECT' and has five rows of data, each with a distinct value for EMAIL_SUBJECT.
We would reference this Column by placing the following value in the Email Subject field:
- :var{EMAIL_SUBJECT}
As a result of this a separate email with a unique subject will be generated for each value of EMAIL_SUBJECT in the Data Table.
Storing and Retrieving the Data Table
Two options are available for storing and retrieving the Data Table:
- Saving it to file and reloading it
- Saving it to a Variable and reloading it
To store the Data Table to a file, use the Write Context to XML Node. This will store the Data Table along with any local, task or global variables in existence. You can then read it back again (in the same Task, or in a separate Task) using the Read Context from XML Node.
To temporarily store a Data Table in memory (for later retrieval) use the Store Data Table and Retrieve Data Table Nodes. These store the Data Table in a Presence variable.
Manipulating the Data Table
Presence provides the following Nodes to manipulate the contents of the Data Table:
- Append Data Column - Appends a new Column onto the Data Table.
- Drop Column - Drops a Column from the Data Table
- Drop Row(s) - Selectively drops rows from the Data Table
- Calculate Column Aggregate - performs aggregate functions on a Column such as sum, average, minimum, maximum, count.
- Dataset Splitter - Splits the Data Table into one ore more sub tables and creates a new Execution Path for each
- Merge Results - Merges multiple Data Tables into a single Data Table
- Clear Data Table - Deletes all Columns and Rows from the Data Table
- Sort Data Table - Sorts the Data Table according to the values in the specified column
- Drop Duplicate Rows - Removes any Rows which are duplicates of existing rows - similar to performing a "SELECT DISTINCT" query.