Drop Duplicate Rows
The Drop Duplicate Rows Node performs the equivalent to a "Select DISTINCT" operation on the current Data Table. Rows that are considered to be duplicates of other rows are removed. A duplicate row is one that contains identical values as another row.
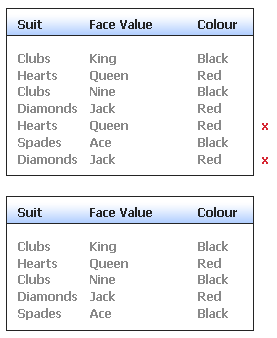
Please see the example below, of a Data Table before and after executing a Drop Duplicate Rows Node (rows which will be deleted are marked with a red cross).
http://www.international-presence.com/wikidocs/images/remove_duplicates_illustration.png
{kind=link}
Selecting columns to consider
The following dialog is displayed when dragging this Node into your Task:
http://www.international-presence.com/wikidocs/images/drop_duplicates_editor.png
{kind=link}
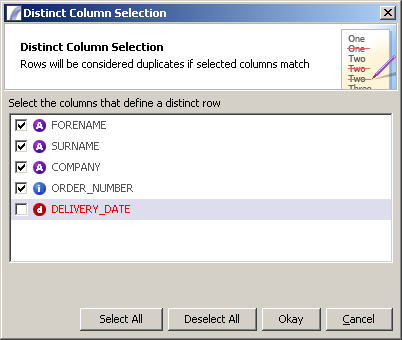
Select which columns you wish to be considered when comparing rows. Any columns which are left unchecked will be ignored when making the comparison - meaning that even though those values differ, provided the checked columns are identical the row will be dropped.
In the example screenshot above only the FORENAME, SURNAME, COMPANY and ORDER_NUMBER will be considered for identicality. Rows containing equal values for these but differing values for DELIVERY_DATE will be dropped (the first row will be retained).
Data Filter | Require Columns | Append Data Column | Multiple Column Appender
Drop Column | Drop Row(s) | Calculate Column Aggregate | Dataset Splitter | Merge Data
Create Data Table | Clear Data Table | Sort Data Table | Drop Duplicate Rows | Store Data Table | Retrieve Data Table
Task Elements > Data Table Nodes > Drop Duplicate Rows