Execution Paths
Execution Paths
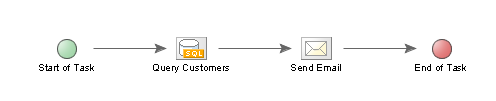
A simple Task may consist on one unambiguous serial Execution Path with a defined start and end, as with the following example:
http://www.international-presence.com/wikidocs/images/linear_task.png
{kind=link}
This is a very straightforward Task - an SQL Query retrieves customer details, and then an email is sent to each customer. Only one serial Execution Path is required, and the Task's general purpose should be quite self-explanatory.
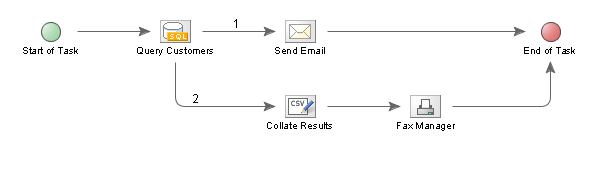
However, there will be many occasions when it is more intuitive to have multiple cascading Execution Paths. For example, in the above example, as well as sending an email you may wish to collate the results from the SQL Query into a single file which will be faxed to a manager. This could be achieved by placing the additional Nodes after the "Send Email" node, or it could be achieved by adding an extra Execution Path:
http://www.international-presence.com/wikidocs/images/cascading_task.png
{kind=link}
When adding one ore more additional Execution Paths, as above, the Task Designer will allocate a number to each Path, starting with 1. This indicates the order in which the Paths will be executed. So in the example above the Task Elements will be executed in the following order:
- 1) Start of Task
- 2) Query Customers
- 3) Send Email
- 4) Collate Results
- 5) Fax Manager
- 6) End of Task
If you wish to change the order that multiple branches are executed, click on one of the paths and use the + / - keys.
Data Handling
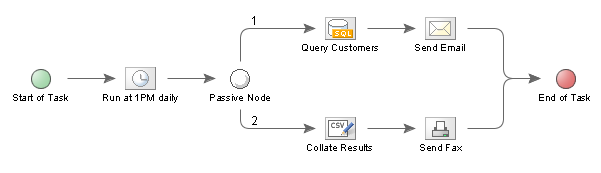
In the above example the data retrieved from the "Query Customers" node will be accessible to both Paths because the Query takes place before the Paths diverge. However, let's look at a different example:
http://www.international-presence.com/wikidocs/images/cascading_task_diverging_data.png
{kind=link}
As you can see in this example, the paths diverge at the "Passive Node" - before the Query takes place on the first Path. This means that the data retrieved in the first branch will not be visible to the second branch, and neither will any Local variables that have been set.