Flat File Parser
Contents
Flat File Parser
This node converts a text file with fixed width fields or character-delimited fields and converts the contents into a Presence data table.
To create a new Flat File Parser in your Task, drag the task element from the Data Access toolbox into the task edit pane. You will then be presented with the editor dialog.
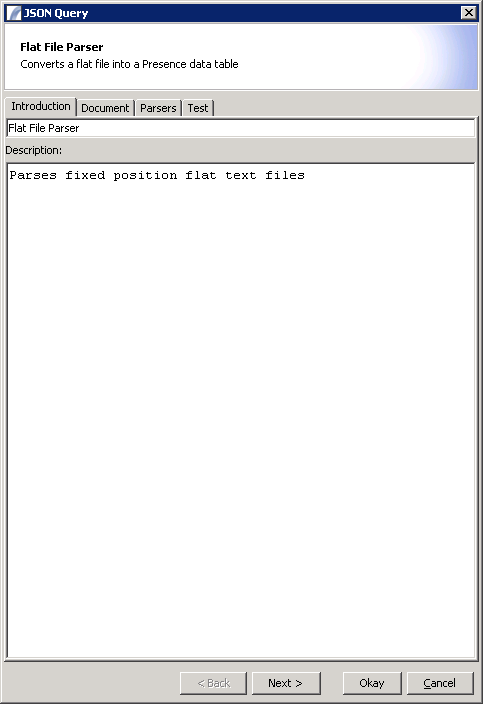
Introduction Panel
This panel allows you to specify a name and description for the node.
http://www.international-presence.com/wikidocs/images/ffp_1.png
{kind=link}
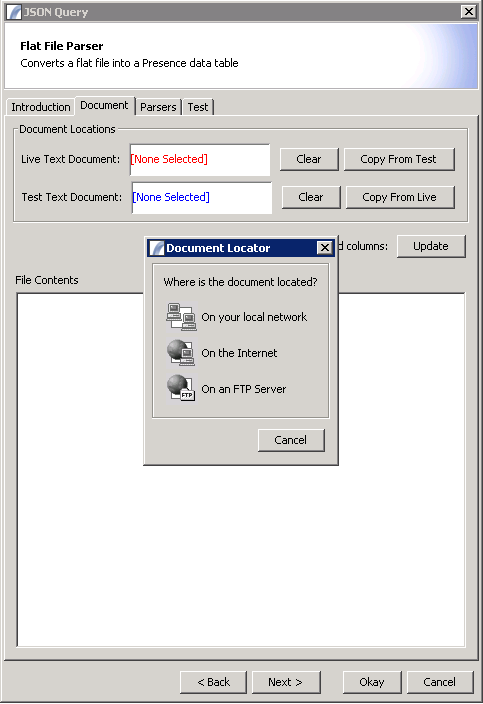
Documents Panel
http://www.international-presence.com/wikidocs/images/ffp_2.png
{kind=link}
The Documents panel enables you to identify the test and live text files. The test file will be used in the development dialog, whereas the live file will be used when the node runs as part of a task on the server.
Click on the document label to choose a local file, a file from the internet, or a file from an FTP server. Once you have selected the files to use, click the Update button to load the file contents into the editor. It will be displayed in the text area underneath the "File Contents" label. You can edit this file for test purposes.
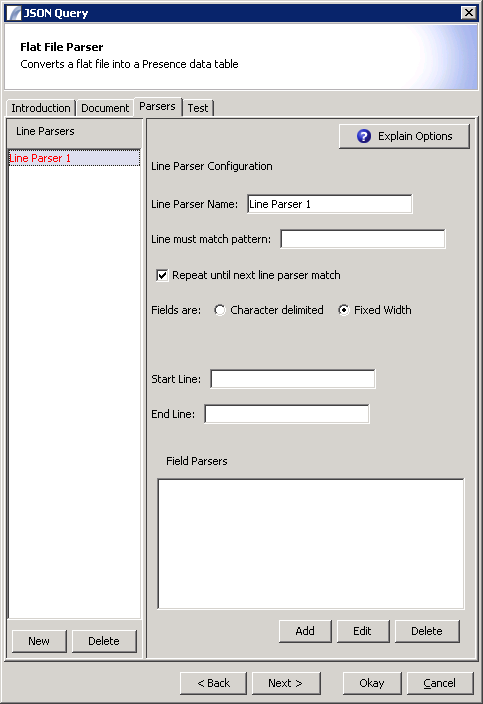
Line Parsers Panel
http://www.international-presence.com/wikidocs/images/ffp_3.png
{kind=link}
Line Parsers are used to identify which lines in the file should be parsed. Lines are identified by a regular expression match, and / or line number. If the regular expression is blank then all lines will be matched.
To the left is a list of line parsers set up for this node. The "New" button underneath creates a new Line Parser which can be edited in the main panel. The "Delete" button removes the line parser. Click on an item to edit it. You can adjust the order of the line parsers by holding down the alt key and pressing the up and down cursor keys.
Line Parser Name This is the name of the line parser and will be shown in the list on the left of the panel.
Line Must Match Pattern This is the regular expression used to identify lines which match this line parser. Some examples are given below:
I\d\d\d\d.* - matches the letter I followed by 4 digits then anything else. [a-zA-Z]{3}\d\d\d.* - matches three alpha characters (a-z or A-Z) followed by three numerics, then anything else CUSTOMER NUMBER:.* - matches the string literal "CUSTOMER NUMBER:" followed by any other characters.
Repeat until next line parser match This will cause the matcher to keep searching additional lines. Otherwise once found it will not be used again.
Line matchers can either look for fixed width fields, where the values are at specific positions in the text, or character-delimited fields. Select the appropriate radio button next to the Fields are: label.
If Character delimited is selected, you will be required to select which character should be used as a delimiter. For example if the line is comma separated, you can use put a comma in this field. Click the button to the right (...) to launch the character map.
Start Line This is the first line that the matcher will look at. Line numbers start with 1. End Line This is the last line that the matcher will look at. Special values for this field are:
- EOF - this represents the end of file
- +n - use the plus symbol to tell the line parser to look for n lines after the first match (eg +5 will look at the 5 lines after the first match)
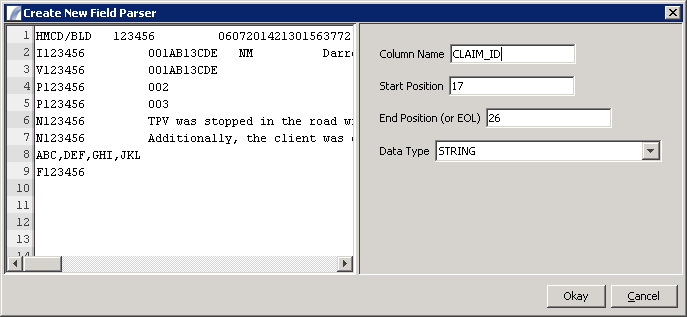
Field Parsers
http://www.international-presence.com/wikidocs/images/ffp_5.png
{kind=link}
Fixed width field parsers are used to specify the positions of the values that the line matcher should read. A list of Field Parsers is displayed underneath the line parser configuration options, if "Fixed Width" fields are selected.
Click Add to create a new Field Parser. This will launch the field parser configuration dialog.
This dialog contains a preview of the document. You can use this preview to select the position of the fields by highlighting portions of the text. This will automatically fill out the Start Position and End Position fields.
You must also specify a column name. This is the column name that will be used in the resulting Presence data table.
Finally, select a data type from the options listed. At runtime, Presence will attempt to convert the string that is read from the file into that data type.
Column Names
If "Character Delimited" fields are selected, a list of column names is made available. This tells Presence the names of the columns to use when generating the data table at runtime, as well as the data types. Use the Add, Edit and Delete buttons to add and remove items from the list. You can re-order items by selecting them and using the alt key together with the up and down cursor keys.
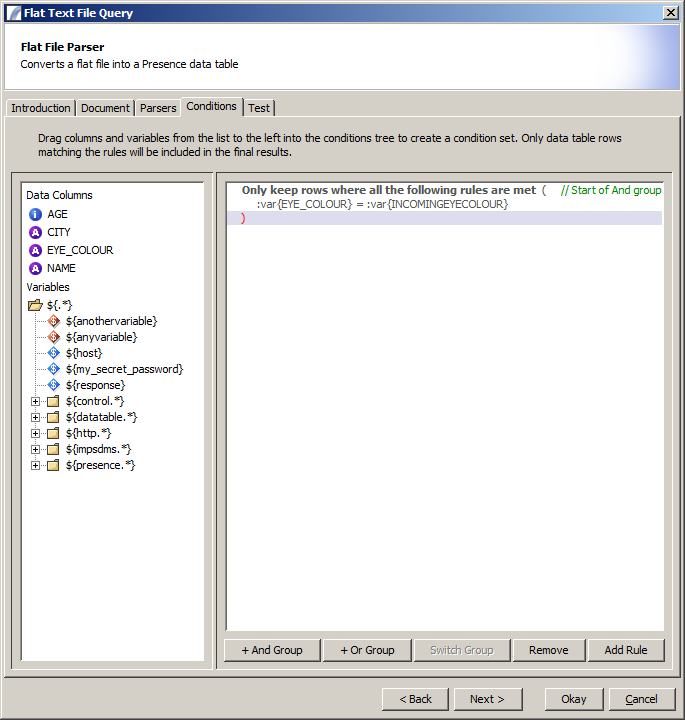
Conditions Panel
Conditions can be applied to the query so that only rows which match the specified rules are included in the final results. This also allows the user to effectively "join" the results of the flat file parser to a previous incoming data table (such as the results of a database query).
http://www.international-presence.com/wikidocs/images/ffp_6.png
{kind=link}
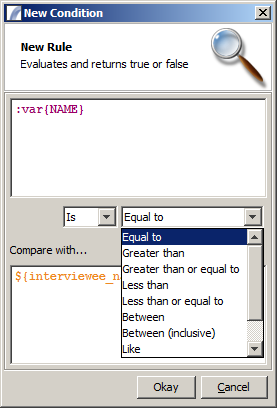
In the left pane is a list of columns and variables which are available on the context. Drag a column or variable into the conditions tree to create a new condition:
http://www.international-presence.com/wikidocs/images/ffp_7.png
{kind=link}
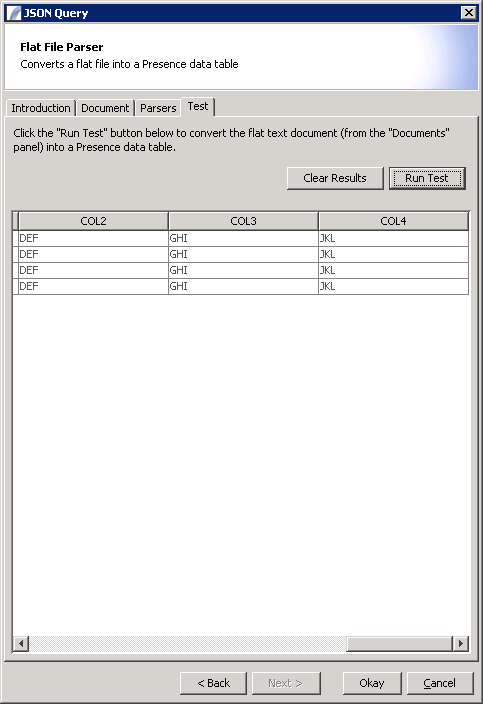
Test Panel
http://www.international-presence.com/wikidocs/images/ffp_4.png
{kind=link}
The Test Panel allows you to test the line parsers and accompanied field parsers with the preview document. Click the "Run Test" button to perform the preview. A table of data will be displayed showing the results of the test.
If variables or columns are referenced, either in the line and field parsers or in the conditions, you will be prompted to enter values for them here. These values will be remembered for future tests.
Note that the results of the test are derived from the preview document in the documents panel, which you may edit. The document is not re-loaded from the source. If you want to re-load the document from the source, click the "Update" button in the documents panel.
See Also
Task Elements : Data Accesss Task Elements : Flat File Parser