Difference between revisions of "XML Query Tool"
m (XML Query moved to XML Query Tool) |
(→Output Panel) |
||
| Line 71: | Line 71: | ||
http://www.international-presence.com/wikidocs/images/xml_dialog_5.png | http://www.international-presence.com/wikidocs/images/xml_dialog_5.png | ||
| − | Here the user can select how to sort the resulting Data Table, or leave items in the order in which they were found in the XML document. | + | Here the user can select how to sort the resulting Data Table, or leave items in the order in which they were found in the XML document. The options on the bottom of the panel allow you to limit the result set returned by omitting duplicate rows using the Distinct Column Chooser: |
| + | |||
| + | http://www.international-presence.com/wikidocs/images/xml_dialog_7.png | ||
| + | |||
| + | In the above panel you would select the columns that should be treated as a duplicate row and omitted where the values are the same. | ||
==== Test Results ==== | ==== Test Results ==== | ||
Revision as of 16:18, 12 August 2015
Contents
The XML Query Node
This Node allows you to perform queries against XML documents and convert the results into a Data Table which is stored in the Presence Context for reference by subsequent Nodes.
In order to query an XML document, you must have access to an XSD document which describes the structure of the XML. If an XSD document is unavailable you can create your own using software such as XML Spy.
XML Query Nodes are re-usable, which means you can create one and re-use in multiple Tasks (or in the same Task). Changes to any instance of an XML Query will affect all other instances.
How the XML Query Tool works
The strategy for querying XML documents in Presence is to convert the document into a flattened table structure (which is how Presence stores data). Because XML documents are multi-dimensional and the relationships between parent, child and sibling nodes need to be preserved this can result in large record sets. Please consider the following example document:
http://www.international-presence.com/wikidocs/images/xml_sample_1.png
{kind=link}
The XML Query tool will internally convert this document into the following flat structure:
http://www.international-presence.com/wikidocs/images/xml_sample_2.png
{kind=link}
This is reasonably concise because there are no repeated elements or elements outside the "person" group. However if the document were to be more complex, as in the following example, the table structure becomes larger:
http://www.international-presence.com/wikidocs/images/xml_sample_3.png
{kind=link}
As you can see an extra element ("disciplinaries") has been introduced as a child of "person". Since the first entry has two such elements this means that there will now be two rows for John Smith instead of just one. As the complexity of the XML document increases so does the size of the resulting data table and the amount of time required to perform the query, so this is something that users should bear in mind when designing their query - limiting the elements included in the resulting data table and defining relationships between elements where possible will help.
Using the XML Query Editor
To create an XML Query Node, right click in your task edit view and select "Create New > XML Query" from the pop-up menu. You will then be presented with the XML Query Dialog:
http://www.international-presence.com/wikidocs/images/xml_dialog_1.png
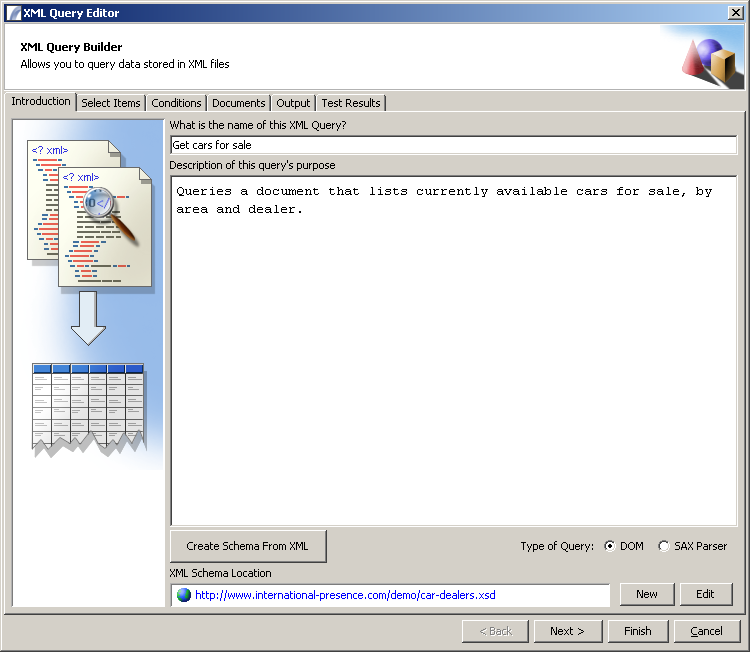{kind=link}
The first panel prompts the user for the following information:
- Name: This is the name to give to this query
- Description: This is a description of the query's purpose
- XSD Location: This is the location of the XSD document which describes the XML structure. It can be on your local network, on the internet or intranet, or at an FTP location.
- Type of Query Select DOM to use the Document Object Model, or SAX Parser to use the (Simple API For XML). Both will produce the same result, but the latter is a newer feature and may be quicker and have a lower memory footprint.
Create Schema from XML
If you have not been provided with an XSD Schema document to describe the XML that you wish to query, use this tool to automatically generate one based on a sample XML document:
http://www.international-presence.com/wikidocs/images/create_xsd_dialog.png
{kind=link}
Select Items Panel
http://www.international-presence.com/wikidocs/images/xml_dialog_2.png
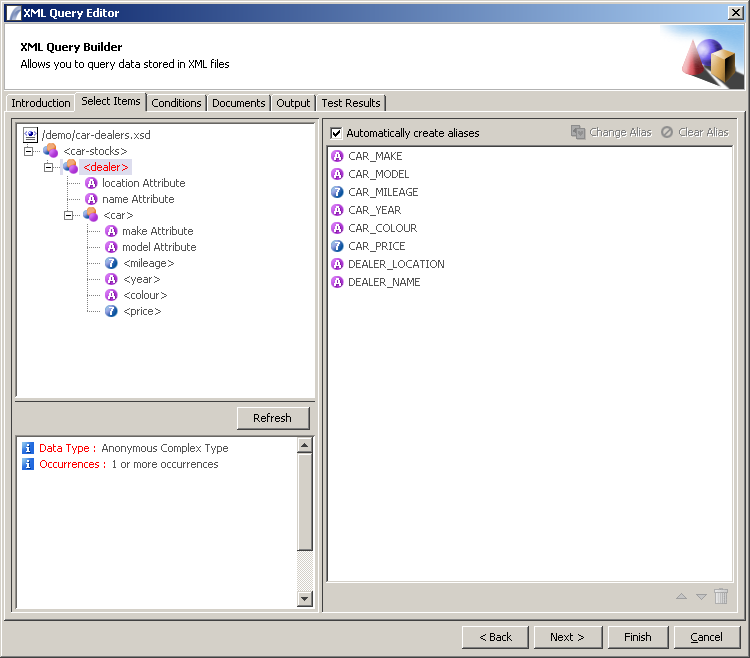{kind=link}
This is the panel that is used to specify which elements and / or attributes you are interested in querying. On the left hand side is a tree-view of the expected XML structure (resulting from the XSD document). To select an element, drag it into the main list pane. Any elements beneath it in the document tree will also be included, as well as attributes.
Aliases will automatically be created unless you uncheck "Automatically create aliases". As with the SQL editor there are also controls to change or remove aliases.
Conditions Panel
http://www.international-presence.com/wikidocs/images/xml_dialog_3.png
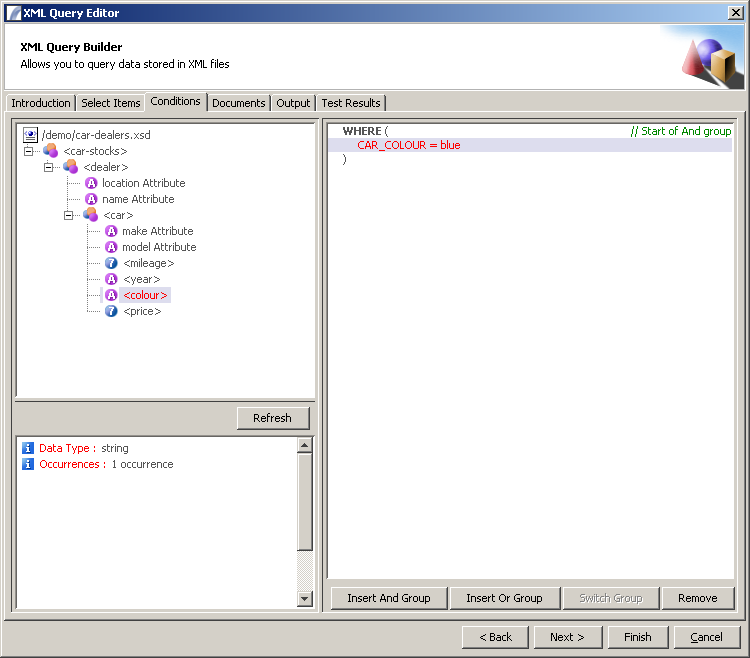{kind=link}
The Conditions Panel allows the user to specify the Rules for element inclusion. Conditions can comprise of static comparisons (e.g. attribute value equals 10), relative comparison (e.g. attribute value equals another attribute value), function calls, data table references, and combinations thereof.
Where relationships exist between sibling nodes you should use the conditions panel to identify them.
Documents Panel
http://www.international-presence.com/wikidocs/images/xml_dialog_4.png
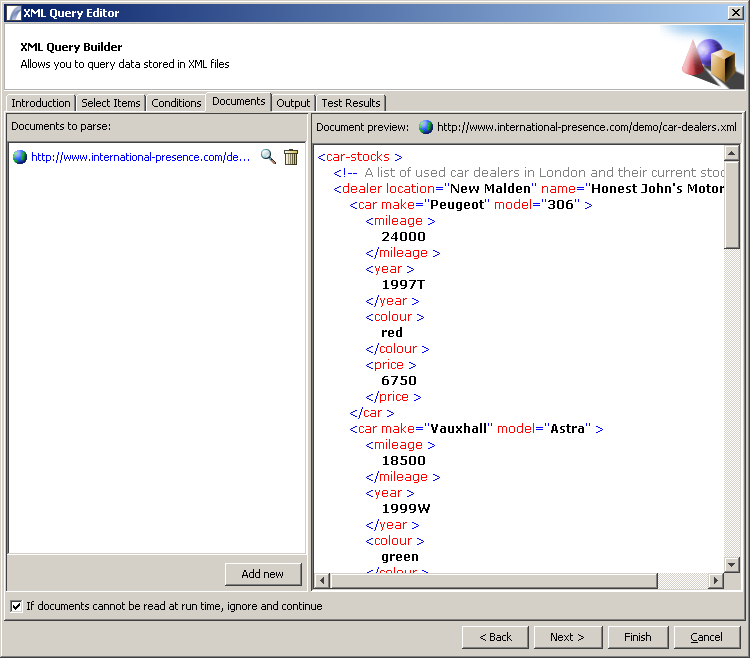{kind=link}
This Panel allows you to specify one ore more documents that should be queried when the node executes. The location can be dynamic - i.e. it can contain a Data Table reference or a Variable reference. Click the "Add New" button to launch the Document Locator, and click on the magnifying glass icon next to a document location to preview the contents in the right-hand pane.
If you wish to skip over any documents that cannot be retrieved (as opposed to throwing an exception) make sure "If documents cannot be read at run time, ignore and continue" is checked.
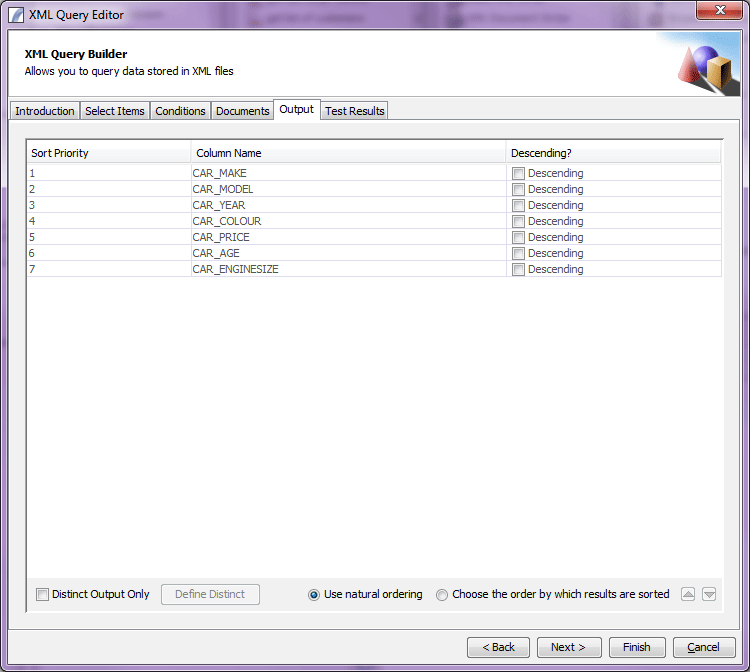
Output Panel
http://www.international-presence.com/wikidocs/images/xml_dialog_5.png
{kind=link}
Here the user can select how to sort the resulting Data Table, or leave items in the order in which they were found in the XML document. The options on the bottom of the panel allow you to limit the result set returned by omitting duplicate rows using the Distinct Column Chooser:
http://www.international-presence.com/wikidocs/images/xml_dialog_7.png
{kind=link}
In the above panel you would select the columns that should be treated as a duplicate row and omitted where the values are the same.
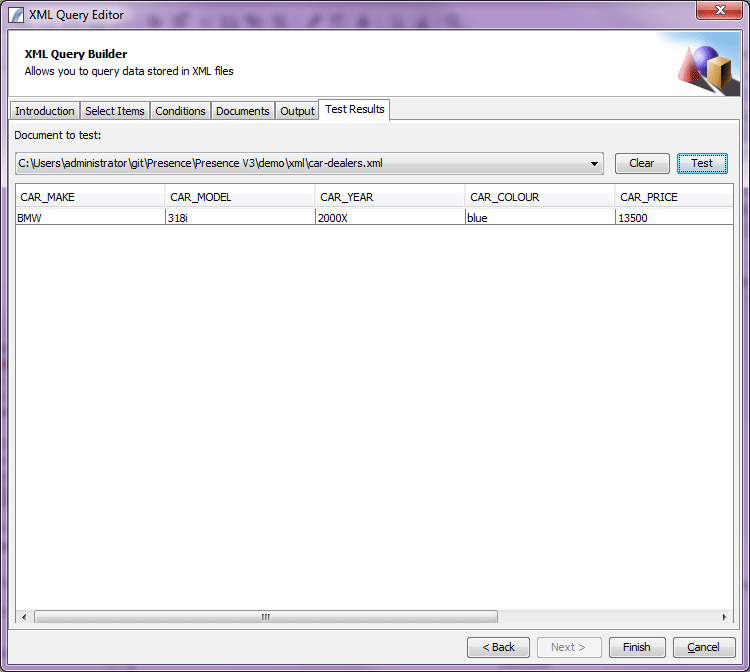
Test Results
This Panel allows the user to test the query against a selected XML document.
http://www.international-presence.com/wikidocs/images/xml_dialog_6.png
{kind=link}
See Also
Task Elements : Data Accesss Task Elements : XML Query Tool